java基础
java基础
基础知识和概念
java语言有哪些特点
- 简单易上手
- 面向对象(封装继承多态)
- 平台无关性
- 可靠性,有自动垃圾回收GC和屏蔽了内存访问和异常捕获机制
- 安全性,有访问修饰符控制访问,防止其他类访问底层细节
- 支持多线程操作
- 很简单的支持网络io等操作
- 编译和解释并存
javaEE和javaSE
- javaEE是java Enterprise edition 即企业版,包括了一些servlet,JSP,JDBC等web开发的工具
- 而javaSE是java Standard edition 即标准版,比较适合用于桌面开发
JDK、JRE、JVM
- JVM即java virtual machine 即java虚拟机,是运行java字节码的虚拟机器,也是java一次编译,到处运行的关键所在,jvm并不是只有hotpot一种,只要满足oracle的规范,自己也可以写虚拟机
- JRE即java Runtime Environment即java 运行时环境,包括jvm以及其他一些运行java程序需要的东西,如java核心类库
- JDK即java devlop kit 即java 开发工具包,包含了开发java程序需要的工具,如javac(编译工具),javalink,javaP,java等工具
为什么java编译和解释并存
- 编译是由编译器将代码编译成更低一级的语言,然后统一运行
- 解释是由解释器逐行将代码解释成低一级的代码如机器码,让后逐行运行
- 我们要先使用javac工具将.java文件编译成更低一级的.class文件,这个过程就是编译的过程,然后由jvm将.class文件逐行解释成机器码,并且解释完后立即执行,这就是为什么java编译和解释并存
AOT有什么优势?为什么不全部使用AOT
- AOT即ahead of time 即运行前编译,即在运行之前就将.class文件全部编译成可执行的机器码文件
- 由于是机器码,就不用使用jvm来进行解释执行了,
- 这样做的好处有
- 占用内存小(不需要JVM)
- 占用空间小
- 启动速度快(不用像JIT那样进行预热和逃逸分析等)
- 劣势
- 做不到像JIT那样的极限性能那么高
- 请求延迟没有JIT高
- 不支持java的一些特性,如反射等
Oracle JDK vs OpenJDK
Java 和 C++ 的区别?
基本语法
基本类型和包装类型的区别?
- 用途:除了定义一些常量和局部变量之外,我们在其他地方比如方法参数、对象属性中很少会使用基本类型来定义变量。并且,包装类型可用于泛型,而基本类型不可以。
- 存储方式:基本数据类型的局部变量存放在 Java 虚拟机栈中的局部变量表中,基本数据类型的成员变量(未被
static修饰 )存放在 Java 虚拟机的堆中。包装类型属于对象类型,我们知道几乎所有对象实例都存在于堆中。 - 占用空间:相比于包装类型(对象类型), 基本数据类型占用的空间往往非常小。
- 默认值:成员变量包装类型不赋值就是
null,而基本类型有默认值且不是null。 - 比较方式:对于基本数据类型来说,
==比较的是值。对于包装数据类型来说,==比较的是对象的内存地址。所有整型包装类对象之间值的比较,全部使用equals()方法。
为什么说是几乎所有对象实例都存在于堆中呢? 这是因为 HotSpot 虚拟机引入了 JIT 优化之后,会对对象进行逃逸分析,如果发现某一个对象并没有逃逸到方法外部,那么就可能通过标量替换来实现栈上分配,而避免堆上分配内存
⚠️ 注意:基本数据类型存放在栈中是一个常见的误区! 基本数据类型的存储位置取决于它们的作用域和声明方式。如果它们是局部变量,那么它们会存放在栈中;如果它们是成员变量,那么它们会存放在堆/方法区/元空间中。
包装类型的缓存机制了解么?
Java 基本数据类型的包装类型的大部分都用到了缓存机制来提升性能。
Byte,Short,Integer,Long 这 4 种包装类默认创建了数值 [-128,127] 的相应类型的缓存数据,Character 创建了数值在 [0,127] 范围的缓存数据,Boolean 直接返回 TRUE or FALSE。
对于 Integer,可以通过 JVM 参数 -XX:AutoBoxCacheMax=<size> 修改缓存上限,但不能修改下限 -128。实际使用时,并不建议设置过大的值,避免浪费内存,甚至是 OOM。
对于Byte,Short,Long ,Character 没有类似 -XX:AutoBoxCacheMax 参数可以修改,因此缓存范围是固定的,无法通过 JVM 参数调整。Boolean 则直接返回预定义的 TRUE 和 FALSE 实例,没有缓存范围的概念。
自动装箱与拆箱了解吗?原理是什么?
什么是自动拆装箱?
- 装箱:将基本类型用它们对应的引用类型包装起来;
- 拆箱:将包装类型转换为基本数据类型;
- 从字节码中,我们发现装箱其实就是调用了 包装类的
valueOf()方法,拆箱其实就是调用了xxxValue()方法
变量
成员变量与局部变量的区别?
- 语法形式:从语法形式上看,成员变量是属于类的,而局部变量是在代码块或方法中定义的变量或是方法的参数;成员变量可以被
public,private,static等修饰符所修饰,而局部变量不能被访问控制修饰符及static所修饰;但是,成员变量和局部变量都能被final所修饰。 - 存储方式:从变量在内存中的存储方式来看,如果成员变量是使用
static修饰的,那么这个成员变量是属于类的,如果没有使用static修饰,这个成员变量是属于实例的。而对象存在于堆内存,局部变量则存在于栈内存。 - 生存时间:从变量在内存中的生存时间上看,成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动生成,随着方法的调用结束而消亡。
- 默认值:从变量是否有默认值来看,成员变量如果没有被赋初始值,则会自动以类型的默认值而赋值(一种情况例外:被
final修饰的成员变量也必须显式地赋值),而局部变量则不会自动赋值。
为什么成员变量有默认值?
- 先不考虑变量类型,如果没有默认值会怎样?变量存储的是内存地址对应的任意随机值,程序读取该值运行会出现意外。
- 默认值有两种设置方式:手动和自动,根据第一点,没有手动赋值一定要自动赋值。成员变量在运行时可借助反射等方法手动赋值,而局部变量不行。
- 对于编译器(javac)来说,局部变量没赋值很好判断,可以直接报错。而成员变量可能是运行时赋值,无法判断,误报“没默认值”又会影响用户体验,所以采用自动赋默认值。
著作权归JavaGuide(javaguide.cn)所有 基于MIT协议 原文链接:https://javaguide.cn/java/basis/java-basic-questions-01.html
接口和抽象类
接口和抽象类有什么共同点和区别?
Object
Object 类的常见方法有哪些?
String
String、StringBuffer、StringBuilder 的区别?
异常
异常关系类图
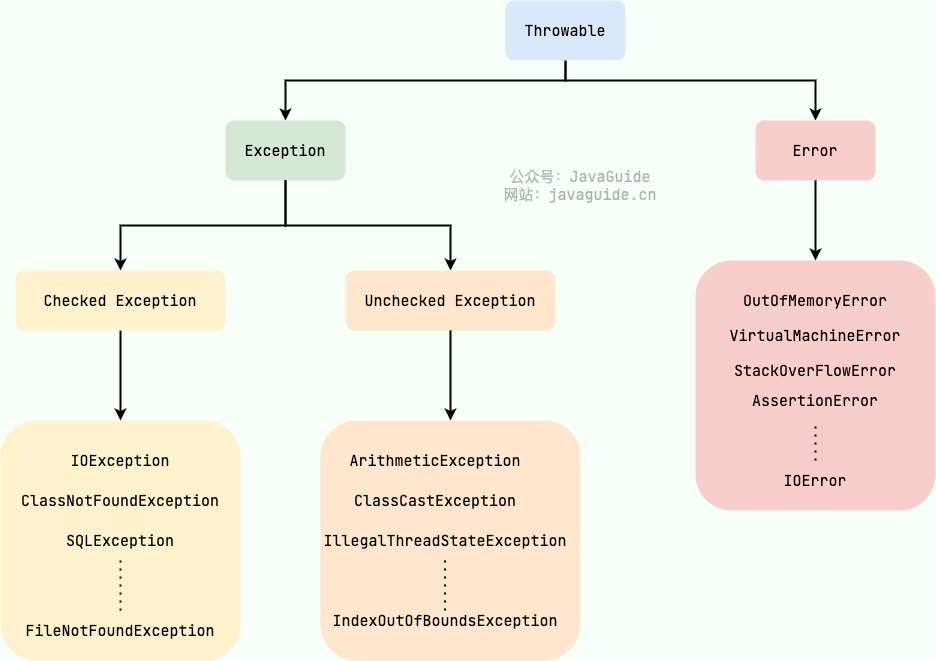
UncheckedException->RuntimeException
RuntimeException 及其子类都统称为非受检查异常,常见的有(建议记下来,日常开发中会经常用到):
NullPointerException(空指针错误)IllegalArgumentException(参数错误比如方法入参类型错误)NumberFormatException(字符串转换为数字格式错误,IllegalArgumentException的子类)ArrayIndexOutOfBoundsException(数组越界错误)ClassCastException(类型转换错误)ArithmeticException(算术错误)SecurityException(安全错误比如权限不够)UnsupportedOperationException(不支持的操作错误比如重复创建同一用户)
为什么不要在finally中使用return语句
当 try 语句和 finally 语句中都有 return 语句时,try 语句块中的 return 语句会被忽略。这是因为 try 语句中的 return 返回值会先被暂存在一个本地变量中,当执行到 finally 语句中的 return 之后,这个本地变量的值就变为了 finally 语句中的 return 返回值。
public static void main(String[] args) {
System.out.println(f(2));
}
public static int f(int value) {
try {
return value * value;
} finally {
if (value == 2) {
return 0;
}
}
}
输出
0
异常使用有哪些需要注意的地方?
反射
何谓反射?
反射的优缺点?
- 优点
- 增加代码的灵活性
- 缺点
- 避开了泛型的安全检查
- 性能稍差
注解
如何自定义自己的注解
要实现一个自动注解,能够在方法上使用该注解时自动将方法签名及其 Object.toString() 的输出内容输出到一个文件中,我们可以通过以下步骤来实现:
1. 定义注解
首先,我们需要定义一个自定义注解,用于标记需要自动记录日志的方法。
java
复制编辑
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(ElementType.METHOD) // 注解应用于方法
@Retention(RetentionPolicy.RUNTIME) // 运行时保留注解
public @interface LogMethodCall {
// 你可以添加额外的属性,比如日志文件路径等
}
详细解释作用
在你给出的代码中,@Target 和 @Retention 是 Java 注解的两个常用元注解,它们用于指定自定义注解的行为。下面是这两个元注解的详细解释:
1.@Target(ElementType.METHOD)
@Target 是一个元注解,它定义了一个注解可以应用的 Java 元素类型。简单来说,@Target 决定了你的注解可以用在哪些地方。
ElementType.METHOD表示这个注解只能应用到方法上。- 除了
METHOD,@Target还可以指定其他值,如:ElementType.FIELD:用于字段(变量)。ElementType.PARAMETER:用于方法的参数。ElementType.TYPE:用于类、接口(包括注解)或枚举。ElementType.CONSTRUCTOR:用于构造方法。ElementType.LOCAL_VARIABLE:用于局部变量。ElementType.ANNOTATION_TYPE:用于其他注解。ElementType.PACKAGE:用于包。
- 除了
通过 @Target(ElementType.METHOD),我们确保了 @LogMethodCall 注解只能被应用于方法,而不能应用于类、字段等其他地方。
2.@Retention(RetentionPolicy.RUNTIME)
@Retention 也是一个元注解,用于定义注解的保留策略,即注解在什么时候有效。它的作用是指定注解在什么阶段仍然可用。RetentionPolicy 是一个枚举类型,它有三种取值:
RetentionPolicy.SOURCE:- 注解只在源代码中存在,编译时会被丢弃。也就是说,编译后,注解将不再存在于字节码中。
- 用途:用于编译时检查或者生成额外代码的工具,如
@Override。
RetentionPolicy.CLASS:- 注解会保留在字节码文件中,但不会在运行时通过反射访问到。
- 用途:适用于不需要在运行时访问的注解。
RetentionPolicy.RUNTIME:- 注解会在运行时保留,因此可以通过反射访问它们。
- 用途:适用于运行时需要使用注解的场景,如 AOP、依赖注入等。
在你的代码中,@Retention(RetentionPolicy.RUNTIME) 表示这个注解会在运行时保留,因此可以在运行时通过反射机制读取它。这样,在方法执行时,我们可以通过 AOP 或其他机制动态地获取带有 @LogMethodCall 注解的方法。
3.@interface注解
- 相当于
public @interface Override {
}
//相当于下面,用于标记这是一个注解
public interface Override extends Annotation{
}
4.结合解释
@Target(ElementType.METHOD):意味着@LogMethodCall只能应用于方法。@Retention(RetentionPolicy.RUNTIME):意味着该注解会在运行时保留,并可以通过反射机制访问它。
2. 使用 AOP 处理注解
为了在方法调用时自动执行记录操作,可以使用 AOP(面向切面编程)。在 Java 中,Spring AOP 是最常用的 AOP 实现。这里的核心思想是,通过 AOP 拦截被 @LogMethodCall 注解的方法,在方法执行前后记录相关信息。
首先,确保你的项目中已经包含了 Spring AOP 的依赖。如果是 Maven 项目,可以添加以下依赖:
xml
复制编辑
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
3. 实现 AOP 逻辑
接下来,我们使用 Spring AOP 来拦截带有 @LogMethodCall 注解的方法,并将方法签名及其 toString() 输出到文件。
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.AfterReturning;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.stereotype.Component;
import java.io.FileWriter;
import java.io.IOException;
import java.lang.reflect.Method;
@Aspect
@Component
public class MethodLogger {
@Pointcut("@annotation(LogMethodCall)") // 定义切点:拦截所有有 @LogMethodCall 注解的方法
public void logMethod() {}
// 方法执行前记录信息
@Before("logMethod()")
public void logBeforeMethod() {
// 记录方法执行前的信息
writeLog("Method called...");
}
// 方法执行后记录信息
@AfterReturning("logMethod()")
public void logAfterMethod(org.aspectj.lang.JoinPoint joinPoint) {
Method method = ((Method) joinPoint.getSignature());
String methodName = method.getName();
// 获取方法的返回值
Object returnValue = joinPoint.getArgs(); // 方法的参数
String logMessage = String.format("Method: %s, Arguments: %s, Return value: %s",
methodName, returnValue, returnValue != null ? returnValue.toString() : "null");
// 将方法签名和返回值写入日志文件
writeLog(logMessage);
}
// 将日志写入文件
private void writeLog(String message) {
try (FileWriter fileWriter = new FileWriter("method_log.txt", true)) {
fileWriter.write(message + "\n");
} catch (IOException e) {
e.printStackTrace();
}
}
}
4. 使用注解
现在你可以在方法上使用 @LogMethodCall 注解,当这些方法被调用时,它们的签名和 toString() 输出会自动记录到 method_log.txt 文件中。
import org.springframework.stereotype.Service;
@Service
public class MyService {
@LogMethodCall
public String myMethod(String param) {
return "Hello, " + param;
}
}
5. 配置 Spring AOP
在 Spring Boot 项目中,AOP 配置通常是自动的,但如果没有,你可以在配置类中启用 AOP。
import org.springframework.context.annotation.EnableAspectJAutoProxy;
import org.springframework.context.annotation.Configuration;
@Configuration
@EnableAspectJAutoProxy // 启用 AOP 支持
public class AppConfig {
}
6. 运行项目
当你运行该项目时,每当调用 myMethod 方法时,MethodLogger 会自动拦截并记录方法签名和返回值到 method_log.txt 文件。
例如,当你调用 myService.myMethod("World") 时,method_log.txt 中将会写入如下内容:
Method called...
Method: myMethod, Arguments: [World], Return value: Hello, World
总结:
- 定义了
@LogMethodCall注解。 - 使用 Spring AOP 来拦截带有该注解的方法。
- 在方法调用前后,自动记录方法签名及其返回值,输出到文件中。
这样,你就实现了自动记录方法签名和 Object.toString() 输出的功能。
注解的解析方法有哪几种?
- 两种
- 编译期直接扫描
- 运行时通过反射来进行注解的解析
SPI
何谓 SPI?
- 即service provider interface,服务提供方的接口
SPI 和 API 有什么区别?
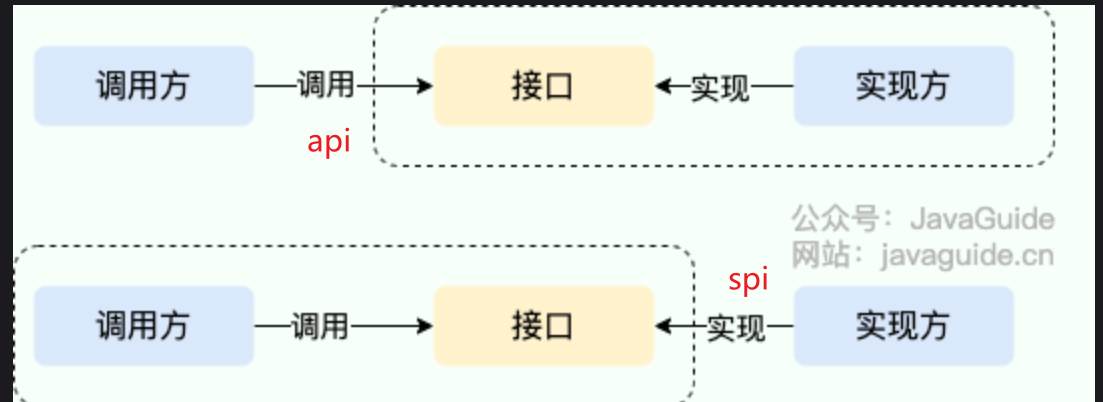
- 主要是看定义的接口是属于谁的
- 如果属于实现方的,那么就是api,主要是强调别人有的功能,你能调用的功能
- 如果属于调用方的,那么就是spi,主要是强调你要给我实现这些功能,我需要什么功能
SPI 的优缺点?
- 优点
- 提升了程序的灵活性
- 缺点
- 不能实现按需加载,效率较低
- 有多个serviceLoader的时候会有并发问题
什么是serviceLoader?
ServiceLoader 是 Java 提供的一个类,位于 java.util 包中,它用于 服务发现机制(Service Discovery)。通过 ServiceLoader,Java 应用程序可以加载和使用一些已经在系统中注册的服务实现,而不需要直接依赖实现类。它的核心思想是实现 SPI(Service Provider Interface) 的自动加载和管理。
1. 什么是 ServiceLoader?
ServiceLoader 是 Java 提供的一个工具类,允许应用程序动态地加载服务实现。它的作用是根据指定的接口(即服务接口)自动查找并加载所有注册的服务提供者实现(即服务的具体实现类),并提供一种统一的方式来使用这些服务。
2. ServiceLoader 的工作原理
ServiceLoader 的工作原理基于 SPI(Service Provider Interface),其通过查找特定路径下的配置文件,发现并加载服务的实现类。
基本流程:
- 定义服务接口:首先,应用程序定义一个服务接口(也称为 SPI 接口),其他开发者或模块提供服务的具体实现类。
- 注册服务提供者:服务提供者(即实现类)将其实现注册到类路径中。注册的方式是通过在
META-INF/services目录下创建一个配置文件,文件名是接口的全限定类名,文件内容是实现类的全限定类名。例如:
META-INF/services/com.example.PaymentService
文件内容:
com.example.impl.CreditCardPaymentService
com.example.impl.PayPalPaymentService
- 使用 ServiceLoader:使用
ServiceLoader类加载和迭代服务提供者的实现。通过ServiceLoader.load(Class<T> service)方法来加载服务接口的所有实现,并提供迭代器供程序访问。
示例:
假设我们有一个支付接口 PaymentService 和它的两个实现类 CreditCardPaymentService 和 PayPalPaymentService:
// 服务接口
public interface PaymentService {
void processPayment();
}
// 实现类 1
public class CreditCardPaymentService implements PaymentService {
@Override
public void processPayment() {
System.out.println("Processing credit card payment...");
}
}
// 实现类 2
public class PayPalPaymentService implements PaymentService {
@Override
public void processPayment() {
System.out.println("Processing PayPal payment...");
}
}
1. 服务提供者的注册:
在 META-INF/services/com.example.PaymentService 中,列出所有实现类:
com.example.impl.CreditCardPaymentService
com.example.impl.PayPalPaymentService
2. 使用 ServiceLoader 加载服务实现:
import java.util.ServiceLoader;
public class PaymentProcessor {
public static void main(String[] args) {
ServiceLoader<PaymentService> serviceLoader = ServiceLoader.load(PaymentService.class);
for (PaymentService service : serviceLoader) {
service.processPayment(); // 调用每个实现的 processPayment 方法
}
}
}
输出:
Processing credit card payment...
Processing PayPal payment...
3. ServiceLoader 的主要方法
ServiceLoader 提供了几个重要的方法来加载和操作服务提供者:
load(Class:加载指定接口的所有服务实现,返回一个service) ServiceLoader<T>实例。iterator():返回一个迭代器,供你遍历所有加载的服务实现。find():返回一个可选的服务提供者实例。reload():重新加载服务提供者,这对于动态更新服务列表时非常有用。
4. ServiceLoader 的特点
- 自动化加载服务实现:通过配置文件,
ServiceLoader可以自动加载所有服务实现,开发者无需显式指定需要加载的实现类。 - 支持多实现:
ServiceLoader可以加载同一个接口的多个实现,并通过迭代器逐个返回实现实例。 - 支持按需加载:服务实现只有在调用时才会被加载,因此不会像传统的依赖注入那样一次性加载所有实现。
- 便于扩展:服务提供者的实现类只需要在
META-INF/services中注册,即可被其他应用或模块发现和使用,非常适合插件化的系统。
5. 使用场景
- 插件机制:
ServiceLoader适用于动态发现和加载插件。例如,JDBC 驱动程序就是通过 SPI 机制来实现的,JDBC 通过ServiceLoader加载各种数据库的驱动程序。 - 模块化架构:
ServiceLoader可以用于模块化架构中,允许开发者提供不同的实现,而不需要更改应用程序代码。应用程序只需要调用接口,而不关心具体实现。 - 接口与实现解耦:
ServiceLoader提供了一种机制,可以将接口和其实现解耦。应用程序可以通过 SPI 接口来调用服务,而不需要依赖于特定的实现类。
6. 优缺点
优点:
- 灵活性:
ServiceLoader使得模块之间的解耦更加灵活,开发者可以动态扩展服务提供者,无需修改应用程序代码。 - 便于扩展:你可以轻松地为接口添加新的实现,只需在类路径中提供一个新的服务提供者,并更新
META-INF/services配置文件。
缺点:
- 性能开销:由于
ServiceLoader会扫描所有类路径上的服务提供者,它可能会带来一些性能开销,尤其是在服务提供者较多的情况下。 - 缺乏按需加载:
ServiceLoader默认一次性加载所有服务实现,不支持真正意义上的按需加载。如果服务实现类非常多,可能会导致不必要的内存消耗和启动时间。 - 不适合复杂的依赖注入:对于更复杂的依赖关系管理,
ServiceLoader不如像 Spring 这样的框架灵活。它没有内建的生命周期管理、作用域控制等功能。
7. 总结
ServiceLoader 是 Java 中用于服务发现的工具,提供了一种机制,通过配置文件动态加载和使用服务实现。它适用于插件化、模块化和解耦的架构中,特别是在需要支持多种服务实现的情况下。虽然它的设计非常简单,但在某些场景下非常有用,尤其是在没有使用全面依赖注入框架时。
然而,它的按需加载能力较弱,无法灵活控制加载时机,因此对于需要更细粒度控制的应用,可能需要结合其他机制或框架来实现更复杂的加载和初始化策略。
序列化
常见序列化协议有哪些?
Hessian、Kryo、Protobuf、ProtoStuff,XML,JSON,java自带的(不推荐)
为什么不推荐使用 JDK 自带的序列化?
更新: 2025-08-14 17:25:18
原文: https://www.yuque.com/duifangzhengzaishuru-rqbua/axyc58/bu460meesslw22wu