算法学习笔记
算法学习笔记
基础语法(java)
计算机常识
- 字符a的ascii码为97,把小a救起来就变成大A了,97来啊
- 字符A的ascii码为65,大香蕉怼我屁屁,那不就是六我嘛,
- 字符0的ascii码为48,死吧,死完了就没了,数量为0
- 既然救起来都要六我,那你们就都死吧
不常见操作符
- 异或(找不相同,即为真)
^表示异或
如
a^b
奇技淫巧
不用第三个变量,交换两个变量值
a=a^b
b=a^b
a=a^b
解释
a=a^b
b=a^b 此时相当于之前的变量值 a^b^b 又因为b^b=0, b=a^0=a
a=a^b 此时相当于a^b^a 满足交换律所以,a=0^b=b
- 按位与(两个都为真,才为真 )
int a=1,b=1;
那么 a&b = 1
奇技淫巧
int a=10 b=16=2^4
如果此时要求 a%b 那么可以-> a&(b-1)
两者是等价的,并且后者更快
注意 b必须是2^n次方,
原理
当b为2^n时,此时换成二进制可以看出,只有从右往左数第n+1位为1,其他位为0
如 2^3 =1000b 2^3-1= 0111b
此时-1的话,就可以把前 n位变成1,那么此时按位与即可求出余数
- 移位
<< 向左移位 ,类似乘2,低位直接补0
>> 带符号向右移位 ,类似除2,这个是带符号位右移,负数高位补1,正数高位补0
>>> 忽视符号位向右移位 ,类似除2,直接右移,高位补0
奇技淫巧
求2的N次方
可以 1<<N
大数字计算
请使用BigInteger(很大的整数)或者BigDecimal(很大的小数)
格式化输出
https://blog.csdn.net/jhsword/article/details/108574442
主要看flag部分
往中间加符号
- 如果你想往输出数组的中间加一个符号,如加号,
- 那么只需要判断当前项是不是最后一项即可
- 是,就输出符号
- 不是就不输出符号
- 简单的加符号,也可以用join
语法注意事项
整数除法和浮点除法
System.out.println((4.0/3)*pi*r*r*r);
和
System.out.println((4/3)*pi*r*r*r);
在这段代码中, 4.0/3和4/3是不同的4.0/3会得到浮点数的答案是正确的答案4/3只会得到整数,即1,默认会舍弃后面的小数部分
工具类
日期操控
calendar(日期计算)
- 常量(常用)
- Calendar.YEAR ——年份 。
- Calendar.MONTH ——月份 。
- Calendar.DATE ——日期 。
- Calendar.DAY_OF_MONTH ——日期,和上面的字段意义相同 。
- Calendar.HOUR ——12小时制的小时 。
- Calendar.HOUR_OF_DAY ——24小时制的小时 。
- Calendar.MINUTE ——分钟 。
- Calendar.SECOND ——秒 。
- Calendar.DAY_OF_WEEK ——星期几。
使用方法
1. 获得实例
```java
Calendar data=Calendar.getInstance();
```java
data.set(2024,Calendar.MAY,1,8,0,0);
参数分别代表 -> 年月日时分秒
2. 设置日期
3. 加减时间
data.add(Calendar.MINUTE, (int) -(10+time));
第一个参数使用calendar中的常量,第二个参数表示加的时间,整数为加,负数为减
SimpleDateFormat (进行时间格式化)
常见格式
- yyyy:年。
- MM:月。
- dd:日 。
- hh:1~12 小时制 (1-12)。
- HH:24 小时制 (0-23)。
- mm:分。
- ss:秒。
- **上面的比较常用**
- S:毫秒。
- E:星期几。
- D:一年中的第几天。
- F:一月中的第几个星期(会把这个月总共过的天数除以 7)。
- w:一年中的第几个星期。
- W:一月中的第几星期(会根据实际情况来算)。
- a:上下午标识。
- k:和HH差不多,表示一天 24 小时制 (1-24)。
- K:和hh差不多,表示一天 12 小时制 (0-11)。
- z:表示时区。
- 使用方法
SimpleDateFormat sp=new SimpleDateFormat("HH:mm");
实例化的时候输入日期的格式,每一位用 : 号隔开,或者用其他符号隔开如 - 号
System.out.println(sp.format(data.getTime()));
保留有效数字
方法
BigDecimal bg=new BigDecimal(h);
//新建一个BigDecimal类
bg=bg.round(new MathContext(2, RoundingMode.HALF_UP));
//使用BigDecimal类里面的round方法,新建MathContext对象作为参数,规定位数,近似方式
System.out.println(bg.doubleValue());
//使用BigDecimal获得值
排序
arrayList排序
例子
ArrayList<Integer> sort = new ArrayList<Integer>();
//生成Arraylist,并给定泛型
for (int i = 0; i < 3; i++) {
sort.add(sc.nextInt());
//添加数据
}
sort.sort(Comparator.reverseOrder());
//使用sort方法进行排序,并给定comparator,如上面的就是从小到大排序,
//如果想逆序,就是用Comparator.naturalOrder()
while (sort.listIterator().hasNext()) {
System.out.println(sort.listIterator().next());
}
搭配使用的comparator
https://blog.csdn.net/Madoka_Homura/article/details/107382799
也可以自己写comparator,本质就是一个lambada函数
Arrays.sort(a,(x,y)->{
if (x[3]>y[3])return -1;
if (x[0]>y[0]&&x[3]==y[3])return -1;
if (x[4]<y[4]&&x[3]==y[3]&&x[0]==y[0])return -1;
return 1;
});
- 如果 a < b,通常返回负数
- 如果 a > b,通常返回正数
- 如果 a = b,返回零
- 这个就是你面自己编写的comparator需要返回的数字
- 逻辑就是 a-b=某个抽象的数,如-1 ,因为-1<0,那么a-b<0
- 1>0 那么a-b>0
- 0=0 那么a-b=0
当比较条件比较单一,并且需要一些转换的操作时
Arrays.sort(a, Comparator.comparing(需要的转换或者访问操作));
Arrays.sort(a, Comparator.comparing(String::valueOf));
Arrays.sort();排序
也可以使用Arrays.sort();进行排序,和上面的排序一样
当你想使用 Comparator.naturalOrder()等方法的时候,数组必须得时Integer和Double等包装类的数组
Integer[] major = new Integer[s[i]];
Arrays.sort(major,Comparator.naturalOrder() );
桶排序
(当默认排序不够快时,可以考虑使用空间换时间,即桶排序)
https://blog.csdn.net/qq_27198345/article/details/126516234
lambada表达式
https://www.runoob.com/java/java8-lambda-expressions.html
流式编程
https://juejin.cn/post/7118991438448164878
https://juejin.cn/post/7121539527151190053
使用parallelstream会更快,但是要注意加锁和同步等问题,重点看14行
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
sc.nextLine();
ArrayList<Integer> list = new ArrayList<>();
StringBuilder sb = new StringBuilder();
sb.append(sc.nextLine());
String[] s1 = sb.toString().split(" ");
Arrays.parallelSort(s1,
Comparator.comparing(
Integer::parseInt
)
);
System.out.println(String.join(" ", s1));
}
}
子集生成
题目 P2415

错误语法
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
ArrayList<Integer> set = new ArrayList<>();
int sum=0;
while (sc.hasNextInt()){
set.add(sc.nextInt());
}
for (int i = 1; i <= set.size(); i++) { //n个元素的子集
for (int j = 0; j <= set.size()-i; j++) { //从第一个开始遍历
for (int k = j; k < j+i; k++) { //遍历i个元素
sum+= set.get(k);
}
}
}
System.out.println(sum);
}
}
- 错误在只关注了连着的子集
正确代码
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
ArrayList<BigInteger> set = new ArrayList<>();
BigInteger sum = new BigInteger(String.valueOf(0));
while (sc.hasNext()){
set.add(new BigInteger(sc.next()));
}
for (int i = 1; i <= (1<<set.size()); i++) { //n个元素的子集,则有1<<n种子集
for (int j = 0; j < set.size(); j++) { //遍历集合中的每一个元素
if ((i&(1<<j))>0){
sum=sum.add(set.get(j));
}
}
}
System.out.println(sum);
}
}
注意第12行
公式推导
自己也可以用二进制进行推导,
对于n个元素的集合,想表示其子集,可以用二进制表示,
如空集(5个元素) 0 0 0 0 0
全集 1 1 1 1 1
那么我们只要考虑每一个元素出现的次数然后再相乘即可,
而每一个元素出现的次数都是一样的,并且我们只需要考虑出现该元素的子集即可
如第一个元素 ,用二进制可以表示一个含有该元素的子集,如 1 0 0 0 0,1 0 0 0 1,
我们观察到,除去一个元素,还有n-1个元素,并且每个元素有0 1 两种可能,
所有含有该元素的子集有 2n-1次方个,即n-1个2相乘,
所以可以求得每个元素的出现次数为2n-1次方

相关知识

正确代码
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
ArrayList<Long> set = new ArrayList<>();
while (sc.hasNextLong()){
set.add(sc.nextLong());
}
BigInteger sum = new BigInteger(String.valueOf(0));
for (int i = 0; i < set.size(); i++) {
sum=sum.add(BigInteger.valueOf(set.get(i)*(1L <<(set.size()-1))));
}
System.out.println(sum);
}
}
优先队列(PriorityQueue)
- 当我们需要维护一个动态极值的数组的时候,我们可以使用优先队列
- 操作
- 构造
- newPriorityQueue<>()
- 直接构造一个优先队列,内部排序使用自然递增排序
- newPriorityQueue<>(Comparator <? super Object> comparator)
- 给优先队列赛一个外部的comparator,
- 这个comparator可以自定义,也可以用java类自带的
- newPriorityQueue<>()
- 查询第一个元素
- poll
- 查询第一个元素并且删除
- peek
- 只查询第一个元素,不删除
- poll
- 添加元素
- add
- 添加一个元素
- add
- 删除元素
- remove
- 删除给定的第一个元素,如果存在
- remove
- 构造
数组填充
Arrays.fill
- 参数一, 要填充的数组
- 参数二,要填充的数字
Arrays.fill(int[],-1)
给前面这个数组填充-1
ArrayDeque
好用的一个工具类,可以模拟栈,也可以模拟队列
| 添加元素到队列尾部 | offerLast()或 offer() |
|---|---|
| 添加元素到队列首部 | offerFirst() |
| 从队列头部移除元素 | pollFirst()或 poll() |
| 从队列尾部移除元素 | pollLast() |
| 查看队列头部元素 | peekFirst()或 peek() |
| 实现栈的压栈操作 | push() |
| 实现栈的弹栈操作 | pop() |
其他注意事项
- 输出结果的最后一行的换行符和空格会自动取消
- 题目字眼
- 保留多少位有效数字和保留多少位小数
- 尽量不要使用java的强制转换,并且要注意隐式转换,因为这样会造成精度损失,如果结果很大,那么一开始就要老老实实的使用long或者使用BigInteger或者BigDecimal,因为我被坑过很多次了
- 约分
- 使用辗转相除法求得最大公约数
- 然后分子和分母都除以最大公约数就可以完成约分
- 注意是第几天而不是第几次****例题 https://www.luogu.com.cn/problem/P5720
- 注意数据的循环起点和重点
- 注意边界值条件以及约束条件
- 扫描时,如果需要扫一行的,需要全部都扫一行,不然第一行的换行符不会被扫掉,从而扫到一个空行,如下所示
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = Integer.parseInt(sc.nextLine());
________________________这里需要扫下一行,而不是扫sc.nextInt(),这样会漏掉一个换行符
for (int i = 0; i < n; i++) {
String[] str = sc.nextLine().split(" ");
String f="";
int result=0;
if (str.length==3) {
operation=str[0];
result=operate( Integer.parseInt(str[1]), Integer.parseInt(str[2]));
f=String.format("%s%s%s=%d", str[1],sign,str[2],result);
}else {
result=operate(Integer.parseInt(str[0]), Integer.parseInt(str[1]));
f=String.format("%s%s%s=%d", str[0],sign,str[1],result);
}
System.out.println(f);
System.out.println(f.length());
}
}
- 对于差一点,但是却TLE的题目
- 建议使用最优的输入输出流而不是其他,如下所示
- 但要注意的是StreamTokenizer会自动识别字符串和数字,对于大数字也会识别成数字,遇到这类题时,建议使用scanner
- 还有输出非常大的时候,一定要即使的flush和使用stringBuilder,不然缓存国道会导致MLE
- 不要使用string.format进输出的格式化,尽量使用stringBuilder,这个东西会消耗非常多的性能,使用stringBuilder!!!!!!!
- 可以减少流的操作,使用stringBuilder
- 建议使用最优的输入输出流而不是其他,如下所示
// 最优输入流
static StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
// 最优输出流
static PrintWriter out = new PrintWriter(new BufferedWriter(new OutputStreamWriter(System.out)));
static int nextInt() throws IOException { // 输入流的封装函数
in.nextToken();
return (int) in.nval;
}
public static void main(String[] args) throws IOException {
out.println(想要输出的东西);
out.flush(); // 刷新输出流
}
参考地址
https://www.runoob.com/java/java-tutorial.html
常见数学概念
闰年
- 能被4整除且不能被100整除的或者能被400整除的
质数
- 求质数易错
private static boolean isZhi(int i) {
// 判断i是否为2、3、5
if (i==2||i==3||i==5){
return true;
}
// 判断i是否为偶数、5的倍数、3的倍数
if (i %2==0|| i %5==0|| i %3==0){
return false;
} else {
boolean flag=true;
// 遍历2到i的平方根之间的数,判断i是否为合数
for (int i1 = 2; i1 *i1<=i; i1++) {
if (i %i1==0){
flag=false;
break;
}
}
return flag;
}
}
- 只需要判断i1*i1,这个就相当于被判断数字的开根号了,只不过这样可以避免开根号带来的小数部分舍弃的问题
i1 *i1<=i注意除数的范围,一定要有= 开跟的结果,不然就少一个因子作为除数,
如:49 =7*7,若没有=号,则判断不出来是质数
注意2也是质数
欧拉筛
判断范围内的质数(欧拉筛法)
- 关键点:就是拿当前的数×之前的筛出来的素数,这个数即为合数
- 为什么要i%Prime[j]==0就跳出循环,下面代码第21行
- 因为 如果 素数j是可以整除i的,即i%素数j==0,那么i*任何数=积 ,这个积都可以除以i
- 如4%2==0,那么 43=12 ,12%2==0 ,45==20 20%2==0,
- 因为乘积里面有4,所以得到的结果都可以被2整除,即2是含有4的乘积的最小质因数,
- 又因为欧拉筛的目的就是只让某个数被最小的质因数标记一次,所以只要i%Prime[j]==0就跳出循环
#include <bits/stdc++.h>
using namespace std;
long long n,m;
bool vis[10000001]={1,1};//0,1均既不是素数,也不是和数,所以先标记为不是
int Prime[10000001],k;
void prime(long long n)
{
for(int i=2;i<=n;i++)//最小的素数是2
{
if(!vis[i])
{
Prime[++k]=i;//如果是素数就标记一下
}
for(int j=1;j<=k;j++)//j小于当前所有的素数的个数
{
if(Prime[j]*i>n)
{
break;
}
vis[Prime[j]*i]=true;//用素数依次×i,结果标记为合数
if(i%Prime[j]==0)
{
break;
}
}
}//欧拉筛法,就是拿当前的数×之前的筛出来的素数,这个数即为合数
}
int main()
{
cin>>n;
prime(100001);//在10的5次方范围内筛素数
for(int i=1;i<=n;i++)
{
int t;
cin>>t;
if(!vis[t])//上面标记过了,这时输入后直接判断就行了
{
cout<<t<<" ";
}
}
return 0;
}
// 静态变量定义
static boolean[] notPrime; // 布尔数组,标记是否为非素数(false表示是素数)
static ArrayList<Integer> curPrimes; // 动态数组,存储当前已筛选出的素数集合
public static void main(String[] args) throws IOException {
int n = nextInt(); // 读取输入的n值
// 初始化非素数标记数组
notPrime = new boolean[n + 1]; // 数组下标范围为[0, n]
notPrime[0] = notPrime[1] = true; // 0和1不是素数
curPrimes = new ArrayList<>(); // 初始化素数集合
// 欧拉筛核心逻辑
for (int i = 2; i <= n; i++) { // 修正:i应遍历到n,确保n自身被处理
// 如果i未被标记为非素数,则i是素数
if (!notPrime[i]) {
curPrimes.add(i); // 将素数i加入集合
}
// 用当前i与已知素数生成合数
for (int j = 0; j < curPrimes.size(); j++) {
int prime = curPrimes.get(j); // 当前素数
int composite = prime * i; // 生成的合数
// 若合数超过n,终止内层循环
if (composite > n) break;
// 标记合数为非素数
notPrime[composite] = true;
// 关键逻辑:若i能被当前素数整除,终止循环
// 保证合数仅被其最小质因数筛除
if (i % prime == 0) break;
}
}
// 输出所有素数(未被标记为非素数的数)
for (int i = 0; i <= n; i++) {
if (!notPrime[i]) out.print(i + " ");
}
// 流操作
out.flush(); // 强制刷新缓冲区,确保内容输出
out.close(); // 关闭输出流
}
最大公约数
辗转相除法
- 参考链接(最大公约数,和最小公倍数求法)
数学归纳法
排列数和组合数的算法
个人总结:
- 排列数只用乘阶乘的前面几个就可以,即上面的数字是取前面的多少个数字
- 为什么是取前面的几个呢
- 如果有六个球有编号,要取4个
- 首先
- 第一次有六种可能
- 第二次有五种可能
- 第三次有四种可能
- 第四次有三种可能
- 根据分步乘法计算原理,依次乘起来就行
- 因为我们要取4次,所以每次取的时候,可能性都会减少1
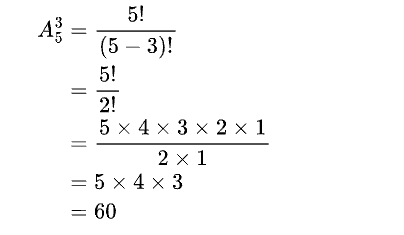
- 组合数只是排列数进行取消排列的顺序,而顺序的可能有3!种,即全前面几个,然后再除以顺序可能即可,在这个图片中
- 为什么顺序有3!种呢,因为在全部球都拿出来后,就只剩3个,对这三个球进行全排序就是3!种
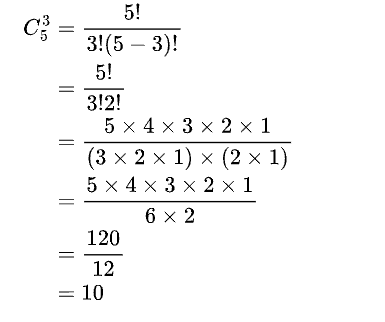
- 最后总结
- 不要混淆排列数和组合数
- 排列数需要一步一步取,是有顺序的,所以需要阶乘来乘以每个阶段的可能性
- 而组合数则是一次性取,不能单纯的使用阶乘,而是要取消排列
- 不要混淆排列数和组合数
数据结构
二叉树
- 满二叉树
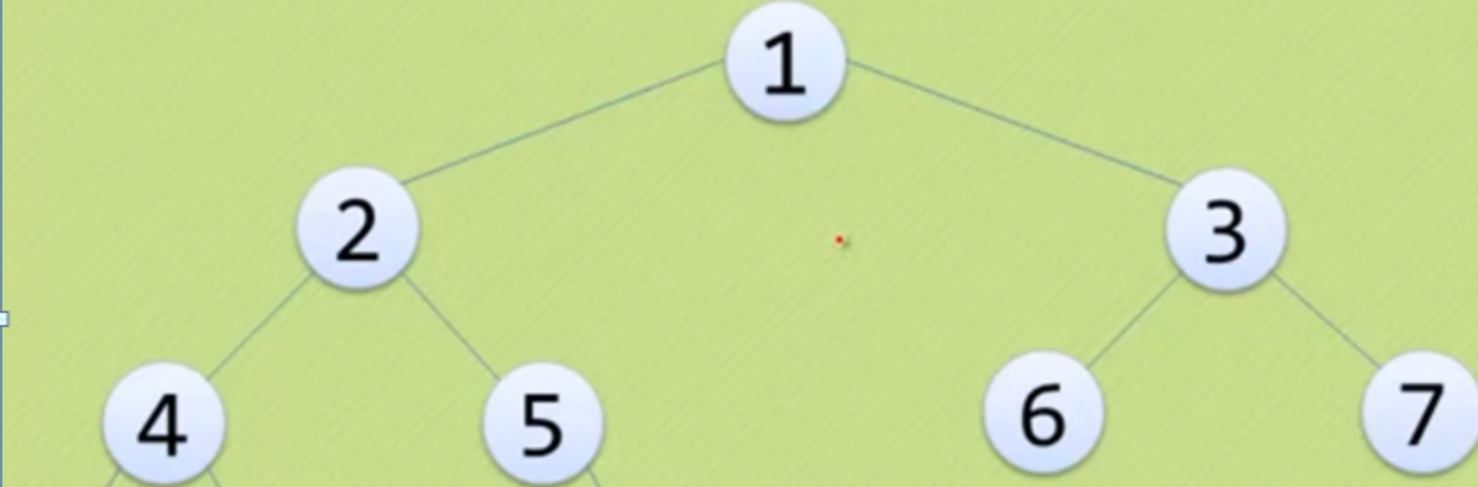
- 完全二叉树
- 完全二叉树是由满二叉树而引出来的,若设二叉树的
深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数(即1~h-1层为一个满二叉树),第 h 层所有的结点都连续集中在最左边,这就是完全二叉树。 - 以下都不是完全二叉树
- 完全二叉树是由满二叉树而引出来的,若设二叉树的


堆
一、堆的基本性质
- 结构特性
- 堆是一棵 完全二叉树,即除了最后一层外,其他层节点必须填满,最后一层节点从左到右填充。
- 堆可以用 数组 高效存储:对于索引
i的节点,其父节点索引为(i-1)/2,左子节点为2i+1,右子节点为2i+2。
- 堆序性
- 小根堆:父节点的值 ≤ 子节点的值(堆顶为最小值)。
- 大根堆:父节点的值 ≥ 子节点的值(堆顶为最大值)。
二、核心操作
1. 插入元素(上浮操作)
- 目标:将新元素插入堆,并维护堆序性。
- 步骤:
- 将新元素添加到数组末尾。
- 上浮(Sift Up):比较新元素与其父节点的值,若违反堆序性(如小根堆中父节点 > 新元素),则交换两者位置。
- 重复步骤 2 直到堆序性恢复。
- 时间复杂度:
O(log n)(树的高度为log n)。
示例(小根堆插入**** 3):
text
初始堆: 5 插入3后: 5 调整后: 3
/ \ / \ / \
8 10 8 10 5 10
/ /
3 8
2. 删除堆顶元素(下沉操作)
- 目标:移除堆顶元素(极值),并维护堆序性。
- 步骤:
- 将堆顶元素与数组末尾元素交换,移除末尾元素。
- 下沉(Sift Down):从新堆顶开始,比较其与左右子节点的值,选择较小(小根堆)或较大(大根堆)的子节点交换位置。
- 重复步骤 2 直到堆序性恢复。
- 时间复杂度:
O(log n)。
示例(小根堆删除堆顶**** 3):
text
删除前: 3 交换堆顶和末尾: 8 调整后: 5
/ \ / \ / \
5 10 5 10 8 10
/ /
8 3(已删除)
3. 查看堆顶元素
- 直接返回数组首元素,时间复杂度
O(1)。
4. 构建堆(Heapify)
- 目标:将无序数组转换为堆。
- 方法:从最后一个非叶子节点开始,向前遍历并对每个节点执行 下沉操作。
- 时间复杂度:
O(n)(比逐次插入的O(n log n)更优)。
示例:
text
初始数组:[9, 5, 2, 7, 3]
构建小根堆:
2
/ \
3 5
/ \
7 9
三、代码实现核心操作
public class MinHeap {
private int[] heap;
private int capacity;
private int size;
public MinHeap(int capacity) {
this.capacity = capacity;
this.heap = new int[capacity];
this.size = 0;
}
// 插入元素
public void insert(int value) {
if (size == capacity) throw new IllegalStateException("Heap is full");
heap[size] = value;
siftUp(size);
size++;
}
// 上浮操作
private void siftUp(int index) {
while (index > 0) {
int parent = (index - 1) / 2;
if (heap[parent] <= heap[index]) break;
swap(parent, index);
index = parent;
}
}
// 删除堆顶
public int poll() {
if (size == 0) throw new IllegalStateException("Heap is empty");
int root = heap[0];
heap[0] = heap[size - 1];
size--;
siftDown(0);
return root;
}
// 下沉操作
private void siftDown(int index) {
while (true) {
int left = 2 * index + 1;
int right = 2 * index + 2;
int smallest = index;
if (left < size && heap[left] < heap[smallest]) {
smallest = left;
}
if (right < size && heap[right] < heap[smallest]) {
smallest = right;
}
if (smallest == index) break;
swap(index, smallest);
index = smallest;
}
}
private void swap(int i, int j) {
int temp = heap[i];
heap[i] = heap[j];
heap[j] = temp;
}
}
class MinHeap{
int size=0;
long[] heap=new long[20001];
public long peek(){
return heap[0];
}
public void swap(int index1,int index2){
long temp=heap[index1];
heap[index1]=heap[index2];
heap[index2]=temp;
}
private void siftUp(int index){
while (index > 0&&index<size) {
int parent=(index-1)/2;
if (heap[parent]<=heap[index])break;
swap(parent,index);
index=parent;
}
}
private void siftDown(int index){
while (index<size){
int lch=2*index+1;
int rch=2*index+2;
int smallest=index;
if (lch<size&&heap[lch]<heap[smallest])smallest=lch;
if (rch<size&&heap[rch]<heap[smallest])smallest=rch;
if (index==smallest)break;
swap(smallest,index);
index=smallest;
}
}
public void add(long data){
heap[size++]=data;
siftUp(size-1);
}
public long poll(){
long smal=peek();
heap[0]=heap[--size];
siftDown(0);
return smal;
}
}
四、一些关于堆的问题
- 为什么小根堆可以保证左子节点小于右子节点
- 不保证
- 父节点索引为 (i-1)/2,左子节点为 2i+1,右子节点为 2i+2。你是不是错了,对于索引为i的节点,父节点索引不应该是 i/2吗,左子节点是2i,右子节点是2i+1
- 在堆的实现中,节点的父子关系索引计算确实存在两种常见方式,这取决于数组的索引起点不同(从 0 开始还是从 1 开始)。以下是两种情况的详细解释:
| 特性 | 索引从 0 开始 | 索引从 1 开始 |
|---|---|---|
| 根节点索引 | 0 | 1 |
| 父子公式 | parent = (i-1)/2 |
parent = i/2 |
| 左子节点公式 | left = 2i+1 |
left = 2i |
| 右子节点公式 | right = 2i+2 |
right = 2i+1 |
| 适用场景 | 编程实现(如 Java、C++) | 教材伪代码(如 CLRS) |
- heap[left] < heap[smallest]这一步是不是错了,子节点不是一定大于父节点的吗
- poll操作要将末尾元素移到堆顶
- 下沉场景:当堆顶元素被删除后,末尾元素被移动到堆顶,此时堆的结构可能被破坏(新堆顶可能比子节点大),需要通过下沉操作恢复堆序性。
- 为什么poll操作要将末尾元素移到堆顶
- 堆是一棵 完全二叉树,即除了最后一层外,其他层节点必须填满,最后一层节点从左到右填充。这种结构特性使得堆可以用数组高效存储,但同时也要求删除操作不能破坏树的完全性。
- 为什么堆一定要是完全二叉树
- 完全二叉树的特性允许堆使用 数组 进行紧凑存储,无需指针或其他复杂结构:
栈
可以使用ArrayDeque来模拟栈操作
- 入栈
- ArrayDeque.push()
- 出栈
- ArrayDeque.pop()
队列
同样可以用ArrayDeque来模拟队列的操作
- 入队
- ArrayDeque.offer()
- 出队
- ArrayDeque.poll()
解题思路总结
- 可以直接暴力求解,遍历每一个输入数据,然后判断
- 数学解
- 根据题目的规律,求解出数学公式,有递归的也行
- 化简数学公式,根据每次递归的规律,再次化简数学公式,(把每次递归或循环的数据带入公式里,然后至少写三项,找出规律,化简公式)
- 直接从题目状态开始递归
- 详细见刷题总结 题目 P1088 火星人的第二种方法
解题技巧
- 可以一边看样例,一边看输入结果和输出结果,这样有利于快速理解题目
- 去除字符串前后的 0可以不用对字符串数组进行操作,只需要记录开始下标和结束下标就行
char[] chars = sb.toString().toCharArray();
int begin=0,end=sb.length()-1;
while (chars[begin]=='0')begin++;
while (chars[end]=='0')end--;
for (int i = begin ; i <= end; i++) {
System.out.print(chars[i]);
}
解题模板
分治法
步骤
- 分
- 搞清楚问题的输入是什么,如为8个球队安排比赛,那么输入就是
8个球队, - 分解成可以解决的m个子问题,
- 搞清楚问题的输入是什么,如为8个球队安排比赛,那么输入就是
- 治
- 将子问题进行求解
- 合
- 将子问题的解合并成输入问题的解
例子


分析
分解搞清楚输入是什么,这道题目输入是8个运动员,8个运动员进行安排很难求解,分解成两个运动员就很容易求解,治理对两个运动员的比赛进行安排 ,如1,2两个运动员就可以表一
| 1 | 2 |
|---|---|
| 2 | 1 |
- 3,4就可以表二
| 3 | 4 |
|---|---|
| 4 | 3 |
- 5,6表三
| 5 | 6 |
|---|---|
| 6 | 5 |
- 7,8表四
| 7 | 8 |
|---|---|
| 8 | 7 |
合并我们发现每一行都是不同的,那么把表二放到表一的右边,那么就安排完了运动员1,2的3天的解,把表1放到表2就安排完了运动员3,4的解,四个运动员再一合并就完成了四个运动员3天的解
| 1 | 2 | 3 | 4 |
|---|---|---|---|
| 2 | 1 | 4 | 3 |
| 3 | 4 | 1 | 2 |
| 4 | 3 | 2 | 1 |
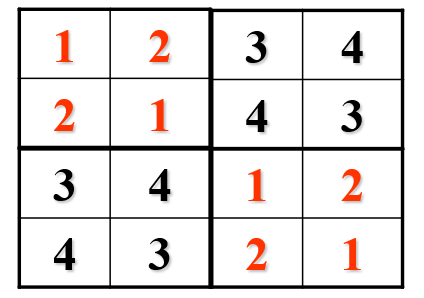
同理可得
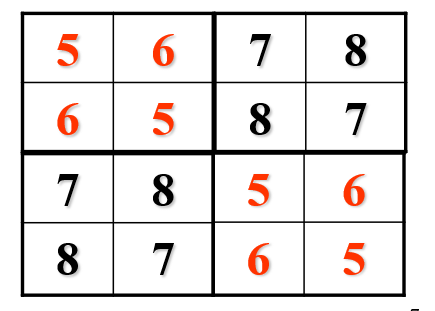
那么再把这两个表格合并,就可以得到原问题输入为8的解
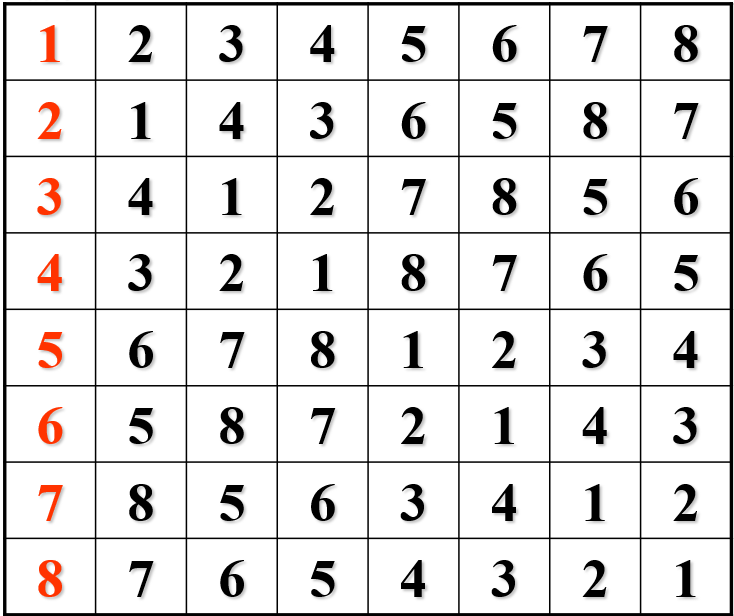
代码
#include <iostream>
#include "iomanip"
using namespace std;
int a[100][100];
void fillTable(int x,int y,int step) {
if (step==1)
{
return;
}
step /= 2;
fillTable(x, y, step );
fillTable(x+step, y, step);
for (int i = 0; i < step; i++)
{
for (int j = 0; j < step; j++) {
a[x + i][y + step + j] = a[x + i + step][y + j];
a[x + step + i][y + step + j] = a[x + i][y + j];
}
}
}
int main() {
int n=0;
cout << "请输入比赛的选手数量" << endl;
cin >> n;
cout << endl;
cout << "日期 ";
for (int i = 0; i < n-1; i++)
{
cout << setw(5) << i + 1;
}
cout << endl;
cout << "选手 ";
for (int i = 0; i < n-1; i++)
{
cout<< setw(5) << setfill('-') << " ";
}
cout << endl;
for (int i = 1; i <= n; i++)
{
a[i][1] = i ;
}
fillTable(1, 1, n);
for (int i = 1; i <= n; i++) {
cout <<setfill(' ') << setw(4) << i << setw(2) << ":";
for (int j = 1; j < n; j++)
{
cout << setw(5) << a[i][j];
}
cout << endl;
}
return 0;
}
动态规划
背包问题
- 定义dp[i][j]数组,明确dp数组的含义,表示前i个物品能放进容量为j的背包的最大价值
- 列出状态转移方程,
- 0-1背包问题的状态转移方程:
$
dp[i][w] = \begin{cases}
dp[i-1][w] & \text
{如果 } w < w_i \
max(dp[i-1][w], dp[i-1][w - w_i] + v_i) & \text{如果 } w \geq w_i
\end{cases}
$- 其中,( dp[i][w] ) 表示在前 ( i ) 个物品中选择,总重量不超过 ( w ) 的情况下可以获得的最大价值。( $ w_i $ ) 和 ( $ v_i $ ) 分别是第 ( i ) 个物品的重量和价值。
- $ dp[i-1][w] $ 如果第 $ i $个物品的重量大于剩余的背包容量,那么就使用当前容量下不放入当前物品的前 $ i-1 $个物品的最大价值即可
- $ max(dp[i-1][w], dp[i-1][w - w_i] + v_i) $表示如果第i个物品的重量没有超过限制,那么就比一下是不放入这个物品的当前容量的前 $ i-1 $个物品的最大价值 和 前$ i-1 $个物品在 当当前容量减去第i个物品的重量 的最大价值加上第 $ i $个物品的价值
什么情况可以使用动态规划
- 重叠子问题(子问题需要重复计算)
- 最优子结构(由子问题可以推出大问题)
要怎么定义动态规划数组
一、核心思路
定义DP数组的关键在于抓住问题中变化的、决定后续决策的核心状态参数,通过状态转移方程描述不同状态间的关系。以下是分步骤指导:
二、参数选择参考标准
| 问题类型 | 典型状态参数 | 选择依据 | 示例 |
|---|---|---|---|
| 路径/移动问题 | 坐标 (i,j) |
当前位置直接影响可达路径 | 过河卒问题中的棋盘坐标 |
| 资源分配问题 | 已选物品数 i+ 剩余容量 v |
物品和容量共同决定后续选择 | 背包问题的 dp[i][v] |
| 操作序列问题 | 剩余操作数 i+ 当前状态 j |
操作改变剩余资源和当前状态 | 栈问题的 f[i][j](队列和栈大小) |
四、定义DP数组的通用步骤
- 识别阶段与决策
- 阶段:问题分解的步骤(如物品选择、移动一步、一次栈操作)。
- 决策:每个阶段可做的选择(选/不选物品、移动方向、压入/弹出)。
- 确定状态参数
- 必须包含 所有影响后续决策的关键信息。
- 参数应尽量 简洁(避免冗余维度),例如:
- 过河卒无需记录路径历史,只需当前位置。
- 栈问题无需记录栈内具体元素,只需数量。
- 处理边界条件
- 初始状态:如背包问题空包的
dp[0][0] = 0,过河卒起点dp[0][0] = 1。 - 终止状态:如栈问题
f[0][j] = 1(队列空时只能弹出栈内元素)。
- 初始状态:如背包问题空包的
- 写出状态转移方程
- 基于决策对状态的影响,如:
- 背包问题:选当前物品则消耗容量并增加价值。
- 过河卒:当前位置路径数等于左侧和上侧路径数之和。
- 基于决策对状态的影响,如:
- 优化状态空间(可选)
- 滚动数组:如过河卒问题中仅保留当前行和上一行。
- 维度压缩:如背包问题的一维数组优化。
五、参数选择避坑指南5
| 常见错误 | 正确做法 | 示例修正 |
|---|---|---|
| 遗漏关键约束参数 | 明确所有影响决策的变量 | 背包问题漏掉容量 → 补充 v |
| 包含冗余参数 | 仅保留必要参数 | 栈问题记录具体元素 → 改为数量 |
| 边界条件未初始化 | 显式处理初始状态 | 过河卒起点未赋初值 → dp[0][0]=1 |
| 状态转移覆盖不全 | 枚举所有可能的决策分支 | 栈问题未处理栈空情况 → 补充分支 |
六、实战训练建议
- 从暴力递归入手:明确所有决策分支后再优化为DP。
- 画状态转移图:用表格或图示理清状态间关系。
- 小数据验证:手动计算简单用例(如
n=2)的DP表。 - 对比题解:学习同类问题的状态设计技巧(如卡塔兰数问题)。
贪心算法
定义 由局部最优解得到全局最优解
步骤
- 找到该问题的贪心选择(这个部分是最重要的)
- 根据贪心选择选择为每一部分选择局部最优解,
例题

输入如下
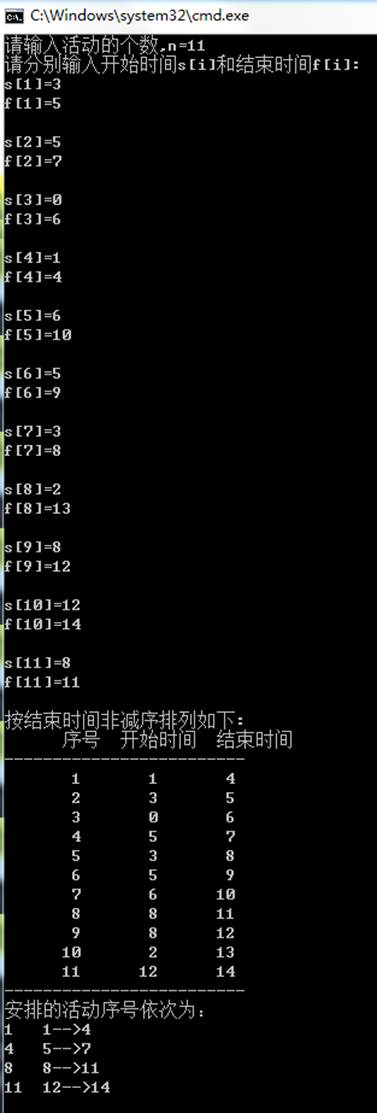
- 找到贪心选择
- 根据贪心算法由局部最优解得到全局最优解,那么这道题目,根据题目的这句话,活动安排问题就是要在所给的活动集合中选出最大的相容活动子集合,所以我们可以得出 ,我们的每次选择就只要选择
活动结束后,剩余时间多的并且活动时间短的活动即可,这样就可以使用剩下的时间去安排更多的活动
- 根据贪心算法由局部最优解得到全局最优解,那么这道题目,根据题目的这句话,活动安排问题就是要在所给的活动集合中选出最大的相容活动子集合,所以我们可以得出 ,我们的每次选择就只要选择
- 根据结束时间进行排序
- 设第一个活动是已选择的,根据上一个已选择的活动的结束时间来寻找下一个选择的活动
- 算法结束
代码实现
#include <iostream>
#include <iomanip>
using namespace std;
int Partition(int s[], int f[], int p, int r);
void quickSort(int s[],int f[],int p,int r) {
if (p<r)
{
int q=Partition(s, f, p, r); //返回pirvot正确的位置,左边都是小于pivot的,右边是大于pivot的
quickSort(s, f, p, q - 1); //对左边排序
quickSort(s, f, q + 1, r);//对右边排序
}
}
int Partition(int s[],int f[], int p, int r) {
int i = p;
int j = r+1;
while (i<j) //易错,双指针有交叉的时候证明排序已经结束,左边是小的,右边是大的
{
while (f[p] > f[++i]);//易错,从左到右扫描,正常的话都是比他小的,比他大的就不正常,退出循环
while (f[p] < f[--j]);//易错,同上
//交叉的时候,j是pivot要插入的位置,为什么呢?
if (i >= j)break;
f[i] = f[i] ^ f[j]; f[j] = f[i] ^ f[j]; f[i] = f[i] ^ f[j]; //异或交换两个变量的值,参考不常见操作符,异或
s[i] = s[i] ^ s[j]; s[j] = s[i] ^ s[j]; s[i] = s[i] ^ s[j];
}
int tempS = s[p];
int tempF = f[p];
s[p] = s[j];
f[p] = f[j];
s[j] = tempS;
f[j] = tempF;
return j;
}
void printArray(int s[],int f[], int begin, int end) {
for (int i = begin; i <= end; i++)
{
cout << setw(15) << i;
cout << setw(15) << s[i];
cout << setw(15) << f[i];
cout << endl;
}
}
void greedySelector(int a[], int s[], int f[], int begin, int end) {
int p = begin; //上一个选的
a[p] = true;
for (int i = begin; i <=end; i++)
{
if (f[p] <= s[i]) {
a[i] = true;
p = i;
}
}
}
int main() {
int n;
int s[100], f[100];
int a[100] = {};//初始化为零
cout << "请输入活动的个数,n=";
cin >> n;
cout << "请分别输入开始时间s[i]和结束时间f[i]:" << endl;
for (int i = 1; i <= n; i++)
{
cout << "s["<<i<<"] = ";
cin >> s[i];
cout << "f["<<i<<"] = ";
cin >> f[i];
cout << endl;
}
quickSort(s, f, 1, n );
cout << "按结束时间非减序排列如下:" << endl;
cout << setw(15) << "序号" << setw(15) << "开始时间" << setw(15) << "结束时间" << endl;
printArray(s,f, 1, n);
greedySelector(a, s, f, 1, n);
cout << "安排的活动序号依次为" << endl;
for (int i = 0; i <= n; i++)
{
if (a[i])
{
cout <<std::left<< setw(15) << i;
cout << s[i] << "->" << f[i]<<endl;
}
}
return 0;
}
深度优先搜索
排列数的dfs
public static void dfs(int size){
if (size==n){
for (int i = 0; i < n; i++) {
sb.append(" ").append(result[i]);
}
out.println(sb);
sb.delete(0,sb.length());
out.flush(); // 强制清空缓冲区
return;
}
for (int i = 0; i < n; i++) {
if (used[i]){
continue;
}
result[size]=i+1;
used[i]=true;
dfs(size+1);
used[i]=false;
}
}
public static void dfs(int size){
if (size==n){
//如果已经搜索到底了,就输出
return;
}
for (int i = 0; i < n; i++) {
if (used[i]){ //剪枝函数,剪掉不满足条件的路径
continue;
}
result[size]=i+1;
used[i]=true; //使用一个boolean数组存储用过的数字
dfs(size+1); //dfs加一层,如果是组合数,就要设置一个begin参数,
// 每次下一个存入的数要比上一个大
used[i]=false; //回溯
}
}
组合数的dfs
public static void dfs(int[]nums,int begin,int r,int n,int size){
if (size==r){
for (int i = 0; i < r; i++) {
out.print(String.format("%3d",nums[i]));
}
out.println();
return;
}
if (n-begin+1<r-size)return;
for (int i = begin; i <= n; i++) {
nums[size]=i;
dfs(nums,i+1,r,n,size+1);
}
}
public static void dfs(int[]nums,int begin,int r,int n,int size){
if (size==r){
//如果已经搜索到底了,就输出
return;
}
if (n-begin+1<r-size)return; //剪枝函数,begin从1开始就要+1,
//不是就不用
for (int i = begin; i <= n; i++) {
nums[size]=i; //注意这里的标号是size,不要写成begin或者i
dfs(nums,i+1,r,n,size+1); //这里的下一个begin是i+1,因为后面的要比前面的大
} //size+1,搜索下一个数
}
直接从某种状态开始的dfs
详细见刷题总结 题目 P1088 火星人的第二种方法
记忆化深度优先搜索
- 当搜索结果有重复的时候,我们可以搜索结果存起来,
- 我们搜索数据或者节点的时候,我们判断这个节点之前有没有搜索过,即有没有值,
- 如果有就返回之前的值
- 如果没有,就可以对这个节点进行深搜索了
参考例题 刷题总结 P1028[NOIP 2001 普及组] 数的计算 的 2. 记忆化搜索
下一个字典序算法
字典序的基本概念:
给定一个排列,我们可以通过交换元素的顺序来生成下一个排列。字典序的生成遵循以下原则:字母/数字越小的排列越靠前。
即刚好比他大的那个排列
例如,给定排列 [1, 2, 3],下一个排列是 [1, 3, 2],而 [2, 1, 3] 是大于 [1, 3, 2] 的排列。
字典序生成的核心步骤
1. <font style="color:#000000;background-color:#D9DFFC;">从后向前查找第一个升序对:</font>
我们从排列的末尾开始,查找第一个满足 a[i] < a[i+1] 的位置,记作 i。这个位置的含义是:如果当前位置不满足升序对,则说明当前排列已经是最大的排列,没有下一个排列可生成。
为什么这样做?
如果我们从后向前检查排列,当我们发现某个元素 a[i] < a[i+1] 时,意味着我们可以对其进行交换来得到更大的排列。
2. <font style="background-color:#D9DFFC;">从后向前查找第一个比 a[i] 大的元素:</font>
接下来,我们需要找到一个比 a[i] 大的元素,并且这个元素应该尽量小(因为上一步找字典序时,后面经过倒叙,后面往前已经是小的了)。为了确保字典序最小,我们从后向前遍历并找到第一个比 a[i] 大的元素 a[j],使得 a[j] > a[i]。
为什么选择 a[j] > a[i]?
这是为了确保交换后的排列不会跳过较大的排列(也就是说,尽量“最小化”交换后的排列),从而生成下一个字典序排列。
3. <font style="background-color:#D9DFFC;">交换 a[i] 和 a[j]:</font>
一旦我们找到 a[i] 和 a[j],我们交换这两个元素。交换后,数组的前半部分已经生成了字典序较大的排列。
4. 反转 i 之后的部分:
交换之后,数组 a[i+1] 到 a[n-1] 这部分是一个递减序列。为了保证这部分元素排列在最小字典序,我们需要将它们进行反转。这是因为,如果这部分已经是最大排列(递减排列),反转后就变成了最小排列(递增排列)。
public class Main {
static StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in))); // 最优输入流
static PrintWriter out = new PrintWriter(new BufferedWriter(new OutputStreamWriter(System.out))); // 最优输出流
static int nextInt() throws IOException { // 输入流的封装函数
in.nextToken();
return (int) in.nval;
}
static Double nextDouble() throws IOException { // 输入流的封装函数
in.nextToken();
return in.nval;
}
static Long nextLong() throws IOException { // 输入流的封装函数
in.nextToken();
return (long) in.nval;
}
public static void main(String[] args) throws IOException {
int n=nextInt(),m=nextInt();
int[] nums = new int[n];
for (int i = 0; i < n; i++) {
nums[i]=nextInt();
}
for (int i = 0; i < m; i++) {
nextPermutation(nums);
}
StringBuilder sb = new StringBuilder();
for (int i = 0; i < n; i++) {
sb.append(nums[i]).append(" ");
}
out.println(sb);
out.flush(); // 刷新输出流
out.close();//关闭流
}
public static void nextPermutation(int []num){
int n = num.length;
int i = n - 2;
for (; i >= 0&&num[i]>num[i+1]; i--);
if (i<0)return;
int j= n -1;
for (; j >i&&num[j]<num[i]; j--);
//交换
num[i]=num[i]^num[j];
num[j]=num[i]^num[j];
num[i]=num[i]^num[j];
for (int k = 1; k <= (n - i) / 2; k++) {
if (i+k==n-k)break;
num[i+k]=num[i+k]^num[n-k];
num[n-k]=num[i+k]^num[n-k];
num[i+k]=num[i+k]^num[n-k];
}
}
}
广度优先搜索
- 定义
- 结构,队列
- 不同于深度优先搜索,广度优先搜索是从当前节点出发,先将所有节点入队,然后再从队列中取出下一个要找的节点,然后才将那个节点的所有可能加入队列
- 步骤
- 定义出发点
- 找到每一个节点的下一层或者下一步的所有可能是什么
- 从队列中取出来队首节点,将该节点所有可能入队
- 如此循环直到队列为空
- 例题
- 请看
刷题总结(分类).P1443 马的分类
- 请看
二分答案
- 定义
- 和二分搜索类似,
- 不同的是,二分搜索,定义搜索的范围
- 二分答案 定义 答案的范围
- 二分答案的题目可以有多个答案
- 二分答案搜索的是可行答案的最优值,
- 并且可行答案最优值的前一个答案也是可行的,并且这两个答案之间有顺序或者某种关系
- 步骤
- 找请是要求谁的最优值
- 找出这个参数的可能的范围
- 考虑清楚check函数,要怎么才能判断这个参数可行
- 如果可行,继续找更大的范围,即left=mid+1;
- 如果不行,找更小的 即right=mid-1;
- 最后找到left>right了
- 就输出结果
- 模板代码
- P2440 木材加工
- 详细解释可以砍刷题总结(分类)中的这道题解析
public static void main(String[] args) throws IOException {
int n=nextInt();
int k=nextInt();
long[] woods = new long[n];
long sum=0;
for (int i = 0; i < n; i++) {
woods[i]=nextLong();
sum+=woods[i];
}
long left=1;
long right= Math.min(sum / k, Arrays.stream(woods).max().getAsLong());
long ans=0;
if (right<1) {
out.println(0);
out.flush();
return;
}
while (left<=right){
long mid =left+(right-left)/2;
long cnt=0;
for (int i = 0; i < n; i++) {
cnt+= (woods[i]/mid);
if (cnt>=k)break;
}
if (cnt>=k){
ans=mid;
left=mid+1;
}else {
right=mid-1;
}
}
out.println(ans);
out.flush(); // 刷新输出流
out.close();//关闭流
}
并查集
- 参考链接
- 定义
- 并查集用于解决图的连通分支数的问题
- 并,即合并,查,及查找,顾名思义,并查集只用合并和查找两种操作
- 详细
- 初始化
- 我们需要一个prev[]数组,来代表每个节点属于哪个分支,默认是自己
- 还需要一个rank[]数组,用于存储秩或者树高或者
每个分支的节点数(默认是这个),默认值为1
- 查找
- 直接返回,x节点的属于的连通分支,如果自己就是连通分支的顶点,就返回,否则就继续往前面寻找
- 但是为了查找更加快速,我们可以使用路径压缩算法
- 每次查找的时候我们就让该节点直接等于该节点属于的连通分支的顶点
- 这样该连通分支的每个节点都等于顶点,这样每次查找的时间复杂度就变成了O(1)
- 合并
- 合并x,y节点,直接让y节点的顶点等于x节点的顶点即可
- 同样的,为了压缩路径,我们可以使用加权合并的合并
- 还记得前面的rank吗,就是在这里使用的
- 如果y节点的顶点的rank比x节点的顶点的rank大,即rank[x的顶点],即y连通分支的节点数比 x的连通分支数小,就让 x的顶点的prev等于 y的顶点即可,然后,rank[y的顶点]+=rank[x的顶点]即可
- 如果小,那就反过来
- 适用于连续编号的并查集算法(并查集优化)
- 代码
- 初始化
class UnionFind{
int[] pre;
int[] rank;
public UnionFind(int size){ //初始化
pre=new int[size];
rank=new int[size];
Arrays.fill(rank,1);
for (int i = 0; i < size; i++) {
pre[i]=i;
}
}
public int find(int x){ //查找
if (pre[x]==x)return x;
return pre[x]=find(pre[x]); //路径压缩
}
public boolean Union(int x,int y){ //合并
int prevX=find(x);
int prevY=find(y);
if (prevX==prevY)return false;
if (rank[prevX]<rank[prevY]){ //按秩合并
pre[prevX]=prevY;
rank[prevY]+=rank[prevX];
}else {
pre[prevY]=prevX;
rank[prevX]+=rank[prevY];
}
return true;
}
}
更新: 2025-09-14 11:55:42
原文: https://www.yuque.com/duifangzhengzaishuru-rqbua/axyc58/an3ggcefc9yo149u